| |
[ Text Corpora ] [ Image Corpora ] [ Lexical Resources ] [ NLP Applications ] |
|
| |
[ How to Order ] |
|
| |
 |
|
| |
CLE is making these linguistic resources available without cost for supporting academic, non-commercial research. The processing fees being charged will be used to maintain these resources. You are requested to contact CLE directly for any discounts (applicable only for selective public organizations in Pakistan) or for commercial licensing options.
|
|
| |
|
|
| |
CLE Urdu Handwritten Image Dataset |
 |
[ Pakistan ] [ International ] |
| |
|
| |
| Source: |
|
| CLE Catalog #: |
CLE23I029 |
| Release Date: |
5 September 2023 |
| Data Type: |
Image |
| Language(s): |
Urdu |
| Distribution: |
1 DVD, Web Download |
| Processing Fee (Pakistan): |
30000 PKR |
| Processing Fee (International): |
250 USD |
| License: |
Yes |
| |
|
|
| |
Introduction |
| |
CLE Urdu Handwritten Lines Dataset is an image corpus having handwritten text lines comprises 8,903 distinct images, all of which were penned by 250 individuals. These writers, ranging from 15 to 30 years old, belonged to various educational institutions, including schools, colleges, and universities. For their writing task, each writer received up to 60 text lines in the form of printed pages. The writers were provided with blank pages having black horizontal lines drawn on them for writing. Writers were instructed to use red pens for writing. Each page was scanned at 300 dots per inch (dpi) and saved using the .jpg format in colored format. After doing some preprocessing, images are segmented into text lines. Each line image was assigned a unique name in the format as aaaa_bbbb_cc.jpg, where aaaa is the identifier of the writer who wrote them, bbbb corresponds to the printed page's identifier that contains the text line in its printed format, and cc identifies the line number on the printed page. The ground truth information of each text line image is also maintained in Unicode file with same name as of image. These images are manually verified and all those lines images along with text files are deleted which are wrongly written. |
| |
|
| |
Data |
| |
This corpus contains two folders. One folder names Images contains 8,903 images of hand written text second folder named GT contains 8,903 text files in UTF-8 file format having ground truth of the typed text line. |
| |
|
| |
Samples |
| |
| Images |
Ground truth |
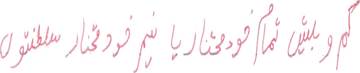 |
کم و بیش تمام خود مختار یا نیم خودمختار سلطنتوں |
| 0001_0251_05.jpg |
0001_0251_05.txt |
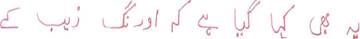 |
یہ بھی کہا گیا ہے کہ اورنگ زیب کے |
| 0002_0252_05.jpg |
0002_0252_05.txt |
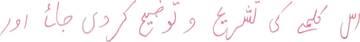 |
اس کلمے کی تشریح و توضیح کر دی جائے اور |
| 0005_0255_06 |
0005_0255_06 |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|